
Iterative Improvements
One takeaway that I really gained first-hand from working on my most recent project is the concept of iterative improvements. In the past, I have always seen iterative software development as a barrier to accomplishment, because I struggled to consider work ‘finished’ until it was packaged in a convenient, ready-to-go takeaway. Palantir’s guiding principle states it nicely by quoting Frederick P. Brooks, ‘Successful software always gets changed.’ Iteration is not a symbol of incomplete or poorly constructed code, but rather indicative of a paradigm of constant improvement.
What sparked these recent thoughts on iterative design has been the (ongoing) process of developing my last application, Playlistr. The main skeleton of the operation is a Mongo database of songs with information corresponding to their artists and contributors. As I build each song document, I create a list of the references to other songs that are made in the Rap Genius annotations. If the referenced song exists in my database, I add the referent’s song id, title, and artist, to further create ties between artists and songs. However, if the song does not exist, this creates another song that needs to be added to the Mongo “library”. It should be clear to see that if this song has any references that are not in my database, a never-ending cycle of querying Genius’ API could be sparked until I’ve downloaded information for the entire site. Even then, new songs are added all the time, and so on, and so on.
Once the Mongo database is updated, I then have to re-run about a third of my code to update my application. The song-by-song matrix pairs every song up against every other song in the database, so new entries will need to be folded in to that analysis. Furthermore, new entries that serve as relational ties between artists can strengthen connections or change existing rankings of relationships between songs. Because of this, “more data is better” holds in the sense that new relationships are always forged.
To recreate that song-by-song matrix I re-weight each contributor’s influence on every song, because I don’t know which songs have newly annotated influencers. Since I am rebuilding the artist-to-song relationship matrix at this point in time, this also is the perfect opportunity to play around with the weights of each contributor category. For instance, if I want a song-by-song matrix that’s more heavily influenced by song references, I can do that at this point. Similarly, if I want to give more influence to writers or producers, that can also be adjusted here. The only rule is that the total weight of all contributors on a song sum to one. The fact that some songs have featured artists, references, and sampled songs while others do not is accounted for by the weighting of the contributors. For instance, I may assign a weight of 6 to writers, 1 to the primary artist, and 10 to a sampled artist. If one song has only a writer, the scores would be 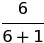 for the writer and
for the writer and 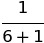 for the primary artist. But if another song has a sampled artist, two writers, and a primary artist, each writer would share the 6 points for a score of
for the primary artist. But if another song has a sampled artist, two writers, and a primary artist, each writer would share the 6 points for a score of 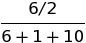 and the sampled artist would be weighted
and the sampled artist would be weighted 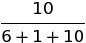 . Meanwhile, the share of the contribution that the primary artist would be awarded would be smaller for the second song since there are more contributor types.
. Meanwhile, the share of the contribution that the primary artist would be awarded would be smaller for the second song since there are more contributor types.
This last point really highlights the beauty of the iterative process. In building out the complexity of my song-to-song relationships, I also have the opportunity to toggle the way that matrix is built. Of course, I can try out many different combinations of these weights and load different settings as I see fit, but the iterative flow of my development cycle gives me a natural chance to check in on the balance of this algorithm and ensure I’m seeing the kind of results I want. Had my song matrix been complete from the very beginning, there would be little motivation to continue tinkering with the weighting of artists. By consistently trying new levels of influence for different contributor types, I have flexibility to adapt my code to my given needs and preferences. This is something I hope to keep in mind as I develop new data products. In construction, the motto is “measure twice, cut once”. In programming, you can build the blueprint once, and “cut” your final product in as many different ways as you like. This is the power of iterative and modularized workflow!

Until next time!
–Em