
Modeling Refugee Crises
Over the past three weeks here at Metis, we’ve completed another machine learning project. The structure of this project was intended to expose us to classification algorithms, MySQL, and Amazon AWS. Although the project was first presented as a group project, we had the option to diverge into individual projects using the same dataset.
My team worked extremely efficiently together, and our project was stronger as a whole because we worked closely. My team was self-selected by a mutual interest in identifying refugee crises. The question we wanted to answer was whether we could predict countries or zones that were at risk for refugee crises. Since everyone needed to implement their own classification algorithm, we designed our question as a meta-learning model, where the inputs to our final model would be outputs from each of our five individual models. Each of us predicted ‘at risk’ or ‘not at risk’, for every country in our dataset for 2013 (the most recent year of data that was available).
The first week was spent doing research on the topic, crafting our core meta-learning model, finding an appropriate question and labeled dataset to use as our y values, and finding data for the features. All of my features came from the World Bank Databank.
At the same time, I set up an Amazon AWS EC2 instance. I used the free micro tier. I installed PostgreSQL on this Ubuntu machine. This would be the database that stored our shared data. My first challenge as a database administrator was to determine the best way for my teammates to read and write to the database. Although the method I chose was not necessarily the most secure, it was simple and served the purposes I needed. This StackOverflow showed me how to open my PostgreSQL port. To refresh my memory on creating user accounts for postgres I turned to Etel Sverdlov’s blog post on Digital Ocean. With this setup, my classmates could access my postgres database using simply my i.p., postgres port, and their username and password. I may write a future blog post going into more detail about the process I used for this.
![]()
Postico, a beautiful GUI for PostgreSQL
During the second and third weeks we built our models. We tested several classification algorithms including K-Nearest Neighbors, Naïve Bayes, Support Vector Machines and Random Forest Classifier.
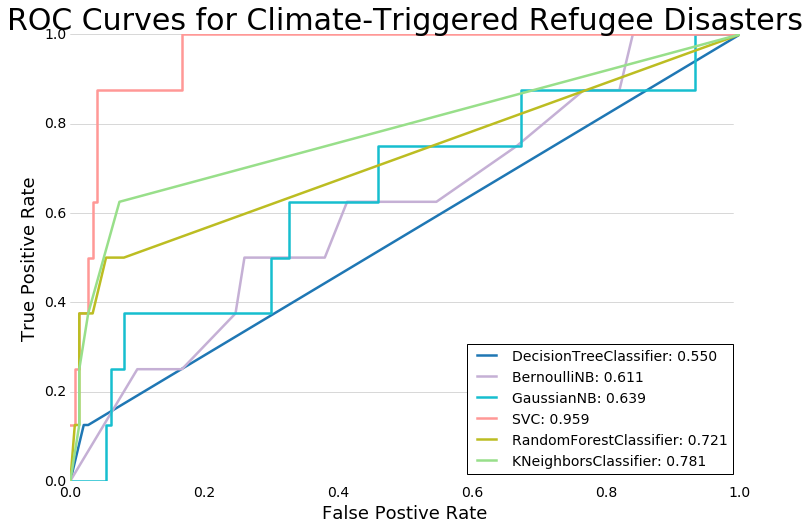
The biggest hurdle to overcome was the disparate sizes of our classes. Since there were relatively few refugee crises in the dataset, our models often predicted with high accuracy. However, my models in particular were performing with recall and precision of 88-95%. At first I realized I was cross-validating on time-series data that occurred after the dates I was trying to predict. Fixing this by creating my own cross-validation sets did not solve my problem of a score that was “too good”. What finally garnered more reasonable results was changing my labels. At first we used a cutoff of a z-score higher than 0 - e.g. any crisis that displaced more than an average number of refugees. My model was much better when I changed my y labels to be the year-over-year change of number of refugees. This was important because the model was failing to predict years when a crisis began or ended - critical years in our model.
The final seventy-two to forty-eight hours before presenting our project was where the real action happened: trying different y labels, adjusting cross-validation sets, creating confusion matrices to illustrate the recall and precision of our models, and creating the meta-learner. Our final model can be found here. The slide deck for this project is available here, and the GitHub for this project is located right here.
This project would not have been possible without the dedication, passion, and talent of my incredible teammates. Thank you to the speedmaster Ken Myers, to Dan Yawitz for his brainstorming and research-fu, to our subject matter expert Kenneth Chadwick, and to our data viz whiz Bryan Bumgardner. Until next time!
-Em